네이버 부동산 크롤링
Naver 부동산 사이트에서 매물 정보를 가져오는 것을 시도해보겠습니다.
INFO
네이버 부동산은 API를 제공하지 않기 때문에, 이렇게 데이터를 가져오는 것은 바람직한 방향은 아닙니다. Crawling크롤링 연습정도로만 참고해주세요
1. 가져올 데이터 탐색
이번 목표는 동탄 아파트의 매매/전세 매물 리스트를 가져오는 것입니다.
실제 매물 정보를 크롤링하여 응용하면 재미있는 뭔가를 만들어볼 수 있을 것 같습니다.
시작은 브라우저를 열고 네이버 부동산에서 아파트를 찾아봅니다.
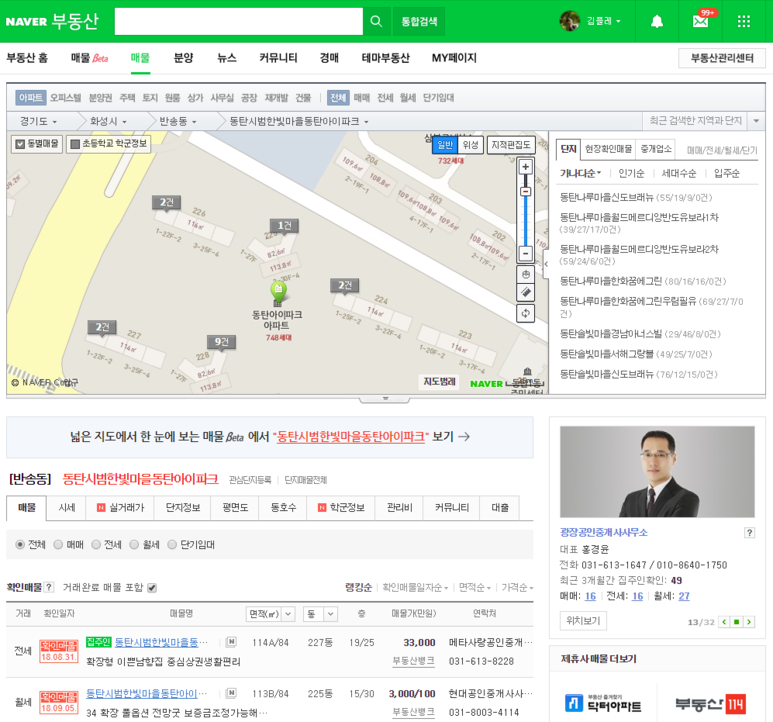
화면 내에 굉장히 많은 정보가 나와있어서 난관이 예상됩니다.
일단 디버깅을 켜보고 화면을 다시 로딩해 봅니다.
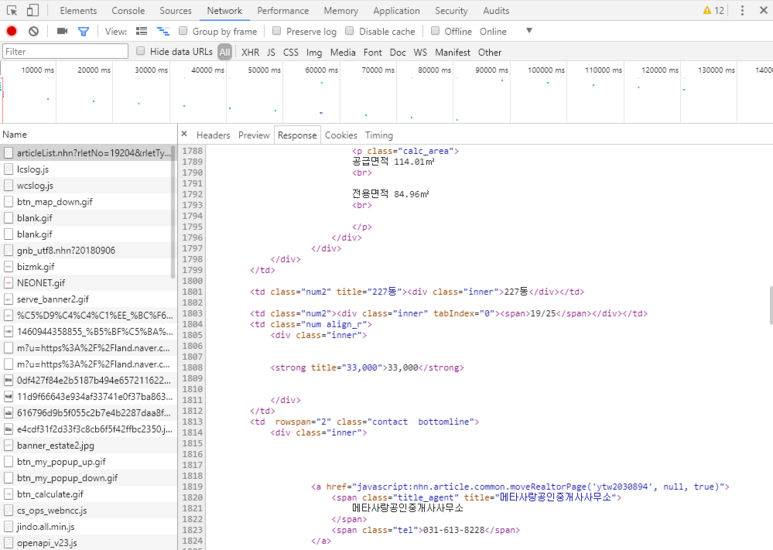
필요한 정보는 https://land.naver.com/article/articleList.nhn?rletNo=19204&rletTypeCd=A01&tradeTypeCd=&hscpTypeCd= 요청으로부터 html을 결과로 얻는것이 확인됩니다.
2. 모바일 페이지 확인
여기서 HTML파싱을 해볼 까 하다가, 귀차니즘 발동으로 모바일용 네이버 부동산 페이지를 열어봅니다.
보통 모바일은 심플한 UI로 구성되기 때문에 적어도 저것보다는 파싱이 쉬운 데이터가 넘어올 것으로 기대해볼 수 있습니다.
https://m.land.naver.com/complex/info/19204?ptpNo=1
매물보기를 눌러보니 답답한 속이 확 풀리는 느낌으로 심플한 리스트가 나옵니다.
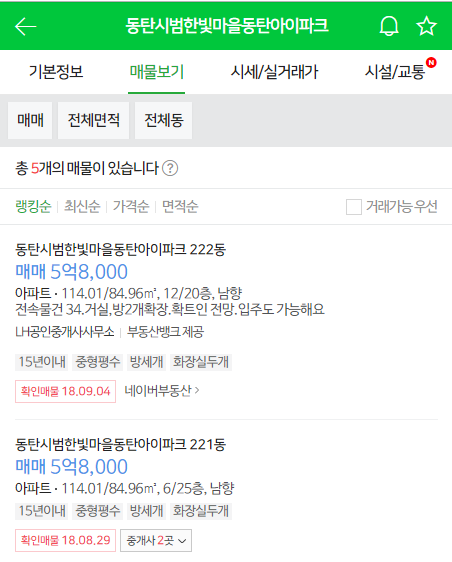
F12를 눌러 JOY를 표합니다.. 가 아니라 요청 내용을 확인해봅니다.
아래 URL결과로 json이 리턴되고 있습니다. (나이스)
https://m.land.naver.com/complex/getComplexArticleList?hscpNo=19204&tradTpCd=A1&order=point_&showR0=N&page=1
별도의 request header가 필요한지 확인하기 위해 URL로 붙여서 결과가 오는지 확인해봅니다.
3. Python 작업 시작
데이터를 얻기 위한 URL 과 parameter를 얻었으니 python으로 작업을 시작 해 봅니다.
INFO
헤더없이 python 작업을 하다보니 네이버에서 봇 감지를 하여 CAPCHA입력 화면으로 넘어갑니다. 역시 네이버 호락호락할리가 없지.. Request header 에 브라우저 정보를 강제로 입력하여 봇이 아닌 척 하고 원래 request header에 들어있던 Referer를 그대로 넣도록 하였습니다.
# -*- coding: utf-8 -*-
import requests
import json
import logging
URL = "https://m.land.naver.com/complex/getComplexArticleList"
param = {
'hscpNo': '19672',
'tradTpCd': 'A1',
'order': 'date_',
'showR0': 'N',
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.220 Whale/1.3.51.7 Safari/537.36',
'Referer': 'https://m.land.naver.com/'
}
logging.basicConfig(level=logging.INFO)
page = 0
while True:
page += 1
param['page'] = page
resp = requests.get(URL, params=param, headers=header)
if resp.status_code != 200:
logging.error('invalid status: %d' % resp.status_code)
break
data = json.loads(resp.text)
result = data['result']
if result is None:
logging.error('no result')
break
for item in result['list']:
if float(item['spc2']) < 80 or float(item['spc2']) > 85:
continue
logging.info('[%s] %s %s층 %s만원' % (item['tradTpNm'], item['bildNm'], item['flrInfo'], item['prcInfo']))
if result['moreDataYn'] == 'N':
break
INFO
headers에 들어가는 정보는 브라우저 디버깅모드에서 확인하였습니다
params에 들어가는 정보는 이것저것 옵션을 변경해가면서 화면을 리로딩하여 확인하였습니다.
결과:
INFO:root:[매매] 448동 28/30층 3억9,000만원
INFO:root:[매매] 450동 3/30층 3억6,000만원
INFO:root:[매매] 450동 4/30층 3억8,000만원
INFO:root:[매매] 448동 15/30층 3억8,000만원
INFO:root:[매매] 444동 10/20층 4억만원
INFO:root:[매매] 448동 14/30층 3억6,500만원
INFO:root:[매매] 448동 29/30층 4억3,000만원
INFO:root:[매매] 448동 16/30층 3억7,000만원
...
4. 결론
네이버 부동산의 매물정보를 가져오는 방법을 알아보았습니다.
위 방법으로는 아파트 코드를 알아야 하기 때문에 모든 지역의 아파트정보를 가져오기는 어렵습니다.
또한, Request를 반복적으로 날리다보면 CAPCHA화면으로 막히기 떄문에 쿼리 속도?를 조절하는 꼼수를 부려야 합니다.
하지만 특정 아파트의 매물 정보를 지속적으로 크롤링 하고 싶다면, 조금 손봐서 사용할 수 있을 것으로 기대합니다.
INFO
위 소스코드는 아래주소에서도 볼 수 있습니다. https://gist.github.com/apt-info/d4f6ee4900afe5d77f6b94216aae89e5